

With all of the buzz around ChatGPT, LLMs, and AI, everyone is hopping on the bandwagon with “support.” But how much of this is fluff vs. reality?
When we initially thought about the company, AI was a foundational focus for the product. This is why we chose devrev.ai when we registered our domain in 2020 (far before this recent hype).
We aren’t just now hopping on the bandwagon; we’ve been preparing for it.
Domain Name: devrev.ai
Registry Domain ID: 982682_nic_ai
Registry WHOIS Server: whois.nic.ai
Creation Date: 2020-06-07T22:25:10.749Z
So what are some of the items that make the platform well-positioned to leverage and embrace AI fully? Let’s check them out.
Just want to see some good examples of how we’re using? Check them out below:
It’s all about the context
For AI models they are only as good as the context (e.g., training data, fine-tuning data and embeddings) they have. For example, both Chat GPT 3.5 and 4.0 were trained on the publicly available internet data as of September 2021, but they lack context about the current state. AutoGPT and others will help with this giving it the ability “fetch” additional context it may be lacking, however…
That’s not the key, the key is in the data that you have that the models don’t have access to.

DevRev: built atop a badass knowledge graph
At its core, DevRev was built to converge the events, products and people (customers, partners and employees) focused around building, operating, supporting, and growing of products. Through the linkage between these objects, we were able to build a powerful knowledge graph that is used to drive every piece of the system.
With the ability to triangulate across these vertices, we can do some really amazing things and provide much more understanding and insight. This is applicable to not only correlation, or clustering (similarity), but brings the power of AI to things like analytics, trend analysis, and prioritization, as well as many more.
By converging things and having a common context, all teams are using; the goal is to enable them to operate as a much more cohesive unit with much higher efficiency and satisfaction.
The following figure is a high-level example of this idea:

The following figure (I know, it’s a lot) shows a real-world example of how we can correlate between product, people (contributors, customers), support, build, opportunities, docs, and a whole plethora of other objects:
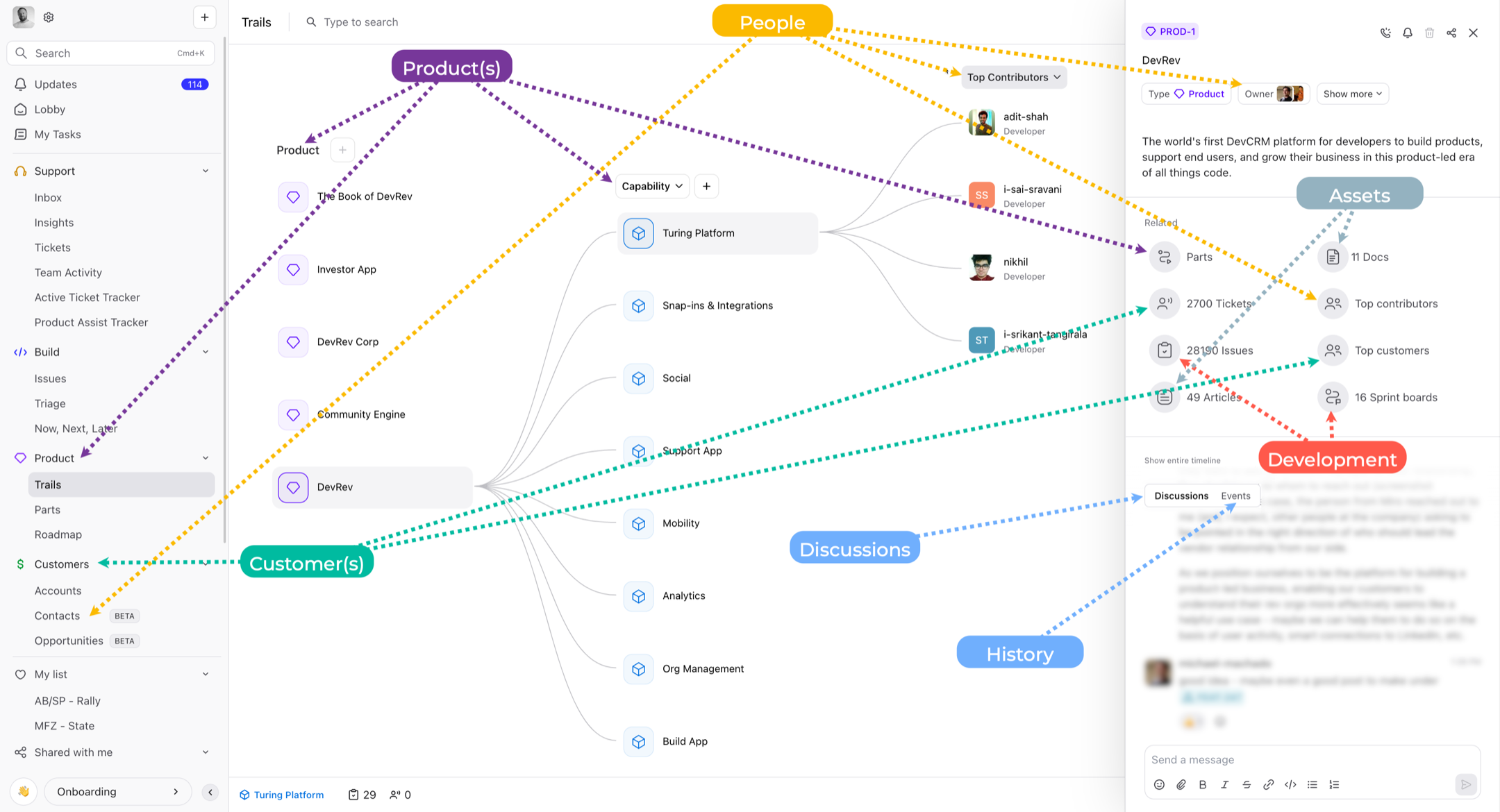
How does this compare to others?
If we compare the types of data in the DevRev system to other point-based solutions, it is clear there’s a large gap in data between them:
- DevRev
- Products
- Customers
- Conversations
- Tickets
- Incidents
- Issues
- Opportunities
- Leads
- Accounts
- Events (e.g., GitHub, DataDog, etc.)
- SFDC
- Opportunities
- Leads
- Contacts
- ServiceCloud
- Tickets
- Customers
- Intercom
- Conversations
- ZenDesk
- Tickets
- Customers
- JIRA
- Issues

Unless someone builds integrations between these systems, they will not have the full context for fine-tuning or embedding. We tried to integrate these systems at our previous company and failed; it’s not an easy problem to solve.
Ok, but why should I care?
When it comes to making decisions or gathering insight, the more context you have the better the decision you can make. Just think about this in real-world scenarios…
When you buy a car do you just consider the features of the car? No, you consider the features, your finances, practicality, terms, what the spouse will say, etc. When you purchase a product, you consider the need, cost, runway, future needs, etc.
Now, say you want to prioritize which work you should focus on and deliver in the next sprint. You’d need information about other items in-flight, staff workload, customer impact of items, dependent opportunities, and a lot of additional data.
With DevRev, we have the full context and can use that to feed into the models. With the other point systems, you’d need to consolidate somewhere manually or lose valuable context which the models need.
Would you trust something making decisions without full context?
We are built to leverage
Coming from Nutanix, we saw a lot of customers looking to move from monolithic systems to those of a more scalable, converged nature.
Because we knew AI would be a crucial part of the system, this impacted how we designed our platform. Affecting things like our service design, delivery architecture, change tracking, object model, analytics and almost everything we’ve done in the system; even the way we designed our interface and UX was built to embrace this.
What are some examples of how we architected things differently?
- We built a badass knowledge graph
- This is at the core of the DevRev platform and is used by every piece of the system
- We have defined links between objects which allows us to keep track of various relationships between objects
- Given this, we are able to easily create graphs of relationships (edges) between objects (nodes)
- This allows us to triangulate and correlate between items (can also be used in vector DB scenarios)
- Using this constructed vector DB we can easily cluster objects across various dimensions (we use this to cluster similar events into an incident, for example)
- We can also triangulate between a customer, product, ticket, issue, and developer allowing us to feed “events” between objects that may be relevant
- We used a flexible document DB instead of traditional relational systems
- Using this structure, we have a ton of flexibility in the document structure, the ability to annotate and extend
- Relational systems can be very rigid and can quickly get messy with a ton of constraints, especially if you haven’t built a ton of abstractions into the data model
- This was key enabler for the next point (customization)
- We built customization in from the start
- We knew extensibility would be key for any platform
- Given the simplicity of customization, we can easily extend our object model with new annotations or context that can be used and fed into models
- This means, that a customer or vendor, can easily extend our object model with new data on objects which can be used by models, new object types, or with the output of a model
- We built multi-tenancy into the object
- Rather than physically segmenting tenant data, we built tenancy into the objects using specific attributes which act as partitions
- This allows us to create macro partitions (e.g., customer) or extremely granular partitions (e.g., user level)
- This gives us a ton of flexibility as all data is in one place and the granularity can range from macro to micro
- We designed our services for the cloud
- Being built in the “era of cloud” we had a lot of very nice tools available to us (e.g. K8s, Lambda, edge computing, WASM, etc.)
- We fully embraced these methodologies allowing us to create a set of very flexible [micro, function, edge]-based services
- This allows us to rapidly scale resourcing (e.g. scale-up/down) and iterate quickly
- Also, by leveraging edge logic and WASM (client-side), we can do some really amazing things (more to come here)
- We are built to iterate quickly
- AI evolves faster than we can imagine; being able to iterate quickly is quintessential to ensure customers get the value of this evolution
- Given the granularity of our services, teams can operate with much more autonomy and speed
- We were also built during the CI/CD era, meaning we have fully continuous integration and delivery. As an example, we deploy hundreds of changes daily
- With monolithic systems, changing things can be complicated as you need to build things at a much more macro level
- Also, some vendors who didn’t grow up in the “as a service” era will need to change processes to embrace CI/CD (some may have)
- A good ask here is how frequently changes are deployed
- When something new comes out, we can react and enable rapidly; others may be slower to enable, leading to a gap between when something is “available” and “really available”
Most of the available items and concepts we had weren’t even ideas when a majority of the other vendors were created. Having gone through a great deal of platform re-architecture, it is a nightmare (if it works).
This means that those vendors can’t simply “bolt-on” AI, or if they do I would question the efficiency of this.
Challenges legacy vendors will have
I think all of these vendors can and will have great potential with AI. However, I see them taking some time and hitting some challenges, some of which they can overcome and others they cannot. Like with everything in life, always perform a litmus test; commonly, the “marketing fluff” looks great, but the reality is far different.
Here are some examples of challenges they may face:
- The lack of full context will hurt their results (they can’t fix what data they don’t have, this is key)
- Inability to adapt quickly enough (it’s a lot harder to move a tanker ship than a small boat)
- Extensive re-design of the UI and backend systems (this will vary between vendors; however, work needs to be done)
- Infighting and politics (having worked for large companies, everyone will want a piece of the pie)
How are we using AI today?
We’ve been using AI models internally for a great deal of time. The following are some examples of areas it is currently in use:
- part discovery
- deflection
- auto part assignment for work items
- summarization
- rephrasing or suggestions
- similar work items
- customer sentiment
TL;DR
- Differentiate between fluff and reality
- DevRev was built to leverage AI fully
- At its core, DevRev built a badass knowledge graph used by all actions and models in the system
- AI will provide great benefits for embracing vendors
- Available data (context) will severely impact the results
- Meaning, systems that only contain a subset of context will have diminished results