

Why we built it
In DevRev Tickets, we capture the invaluable feedback of our customers through bug reports and feature requests. Each ticket contains a concise title summarizing the customer’s request, accompanied by a detailed description. It’s not uncommon for multiple customers to encounter the same issue or express interest in the same feature. This can lead to redundant data in our system, requiring manual sorting by the team.
Fortunately, DevRev offers an innovative solution! As you craft the title for a new Ticket, our platform intelligently suggests potential duplicates, streamlining the process and preventing the creation of redundant tickets. This feature not only saves time but also ensures that we efficiently address our customers’ needs by identifying existing solutions or reports.
The excitement lies in the complexity of suggesting duplicate tickets, given that customers naturally express themselves in unique ways. It would be unreasonable to expect different customers to use identical wording when they describe a problem. Traditional syntactic searches rely on precise keyword matches for identification, assuming the use of identical words.
Let’s consider an example to understand the difference.
If we have tickets with the following titles, the keyword search will suggest that TKT-1 and TKT-2 are similar though they are not reporting the same problem. TKT-1 and TKT-3 are very similar though they do not use the same words.
TKT-1: I have a problem with the product.
TKT-2: I have a problem with the people.
TKT-3: I would like to report an issue with the app.
We needed a search system that goes beyond keywords, prioritizing meaning and context. This specialized search method is referred to as Semantic Search. Semantic Search is a driving force behind numerous use cases in DevRev. It seamlessly integrates with our syntactic search to offer a hybrid search approach. However, for this post, our main emphasis will be on delving into semantic search which is a core building block.
What we built
Semantic similarity refers to the degree of likeness or resemblance in meaning between two pieces of text, words, or concepts. We use embeddings generated by Machine learning models to represent text. Embeddings are a way of representing words or entities in a continuous vector space, where the proximity of vectors reflects semantic similarity. So to identify the ticket closest to the query title text, we would need to find the ticket embeddings closest to the query embedding.
How we built it
The semantic search system has to index all the tickets in the system and retrieve those similar to the title of the ticket provided. I am going to structure this section into three components, System requirements, Architecture and Decisions.
System Requirements
DevRev is a multi-tenant platform offering a freemium tier and expects semantic search to power many features like object similarity search, deflections and retrieval augmented generation.
- The search system must support multi-tenancy.
- The system must scale to millions of tenants each storing millions of vectors.
- The data is constantly changing, so the system must be capable of tracking and handling updates.
Architecture
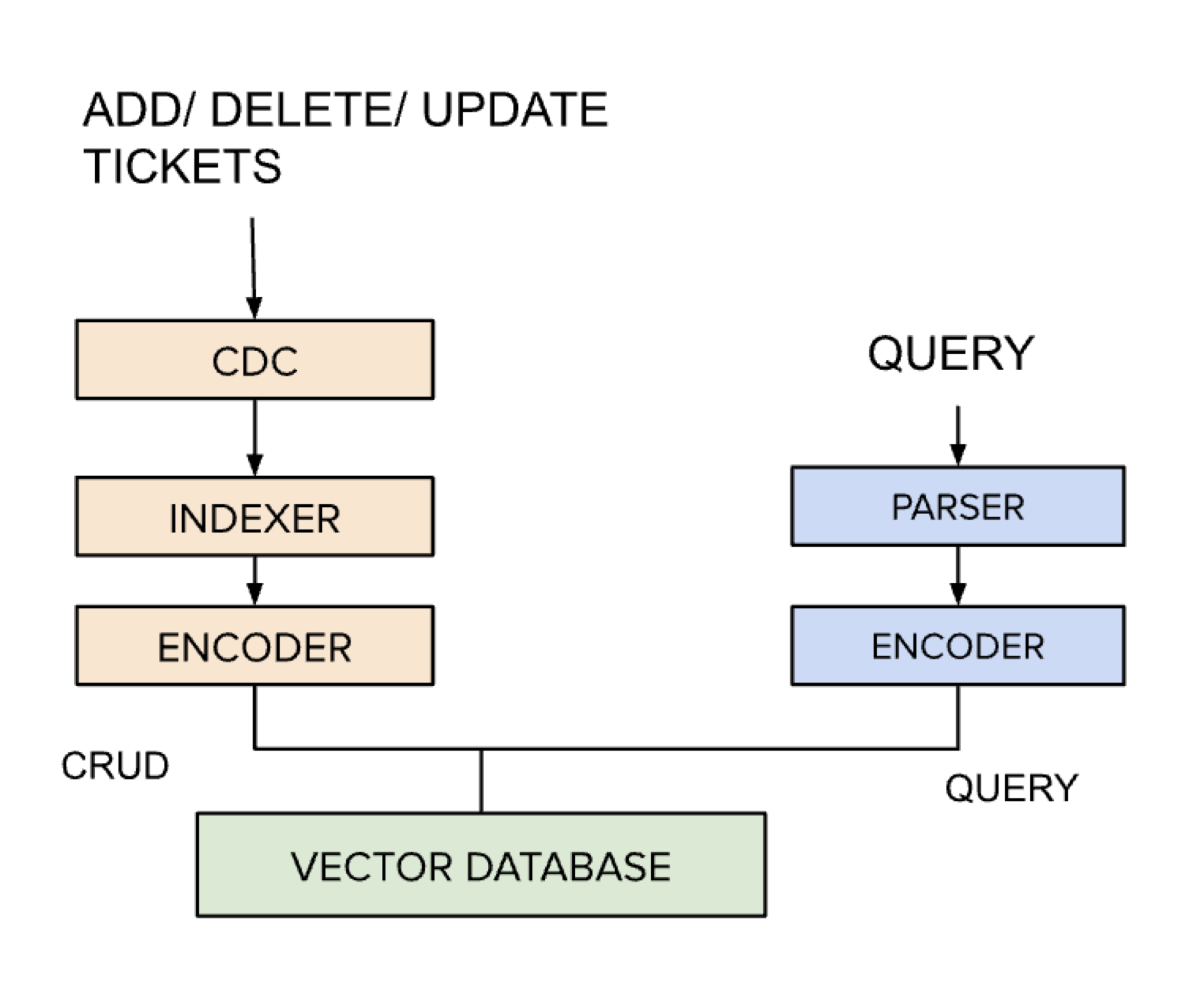
Let’s dive into each of the blocks in this architecture diagram to understand how the pieces fit together. The diagram shows two flows: index population and retrieval. The left side talks about the blocks that get invoked when the data in the system is updated in any way. In our context, this would be Tickets getting added, updated or deleted. The text fields in the ticket are converted into a vector representation and persisted in the vector database in the form of indexes for retrieval. The right-hand side depicts how every search query is converted into a similar vector representation before it accesses the vector database for retrieval.
Change Data Capture (CDC)
The Change Data Capture Module is a Kafka-based system that tracks and captures the create, update and delete operations on the ticket object in the system. The accuracy of the search results are dependent on ensuring the data is not stale.
Parser
We support a search query language that allows for the definition of filters and namespaces. The parser interprets the filter expression language and extracts the part of the query that needs to be encoded. In our example, this would involve extracting text in the query along with any filters that may narrow our search space.
Encoder
The encoder is the component that converts the text into a vector representation using an embedding model. This is required to capture the meaning and context and enable semantic search. The choice of embedding model is an interesting topic that I will discuss later in the article when we talk about decisions.
Indexer
Every ticket object is encoded and the resulting vectors are stored in the vector database. The indexes are populated initially when the customer data is onboarded and will need to execute periodically to store the changed data. There are many factors based on which a new index may be introduced ranging from new object namespaces and embedding models to additional filters. So we have found it useful to have a configurable indexer framework that can be extended easily.
Vector Database
Determining the similarity of objects involves calculating the distances between the object’s vector embeddings. However, this process requires comparing the distances between the query vector and every vector in the index, posing scalability challenges when dealing with millions or billions of vectors. Vector Databases are optimized to perform this calculation efficiently using the Approximate Nearest Neighbor Search Algorithm.
Decisions and Reasoning
We made a series of design choices and I will share our thought process around them.
How did we choose the embedding model?
The choice of embedding model dictates the accuracy of the Semantic Search. Given the rate of advancement of the models, it is necessary to build a mechanism that can easily evaluate new models and adopt them if necessary. We track the MTEB Leaderboard to stay informed of the latest benchmarks and run experiments to evaluate embeddings for our use case based on the following metrics.
Latency - The time it takes for the model to return results. Lower latency leads to a better user experience.
Precision - % of retrieved results that are relevant to the query.
Recall - % of total relevant results that are retrieved. Recall of ~80% is reasonable.
Resource Utilization: CPU and Memory utilization must be reasonable.
This is a heat map depicting the embeddings for the example titles we considered above. The semantic scores listed in the grids measure the similarity between the tickets. This is a great way to visualize the experiments with different embeddings and a test data set. You will notice that every ticket matches itself 100% and is denoted by a 1 in the heatmap grid. You will also notice that the similarity score when TKT-1 and TKT-3 are compared is higher than when TKT-1 and TKT-2 are compared. This is exactly the result we were hoping for when we started!
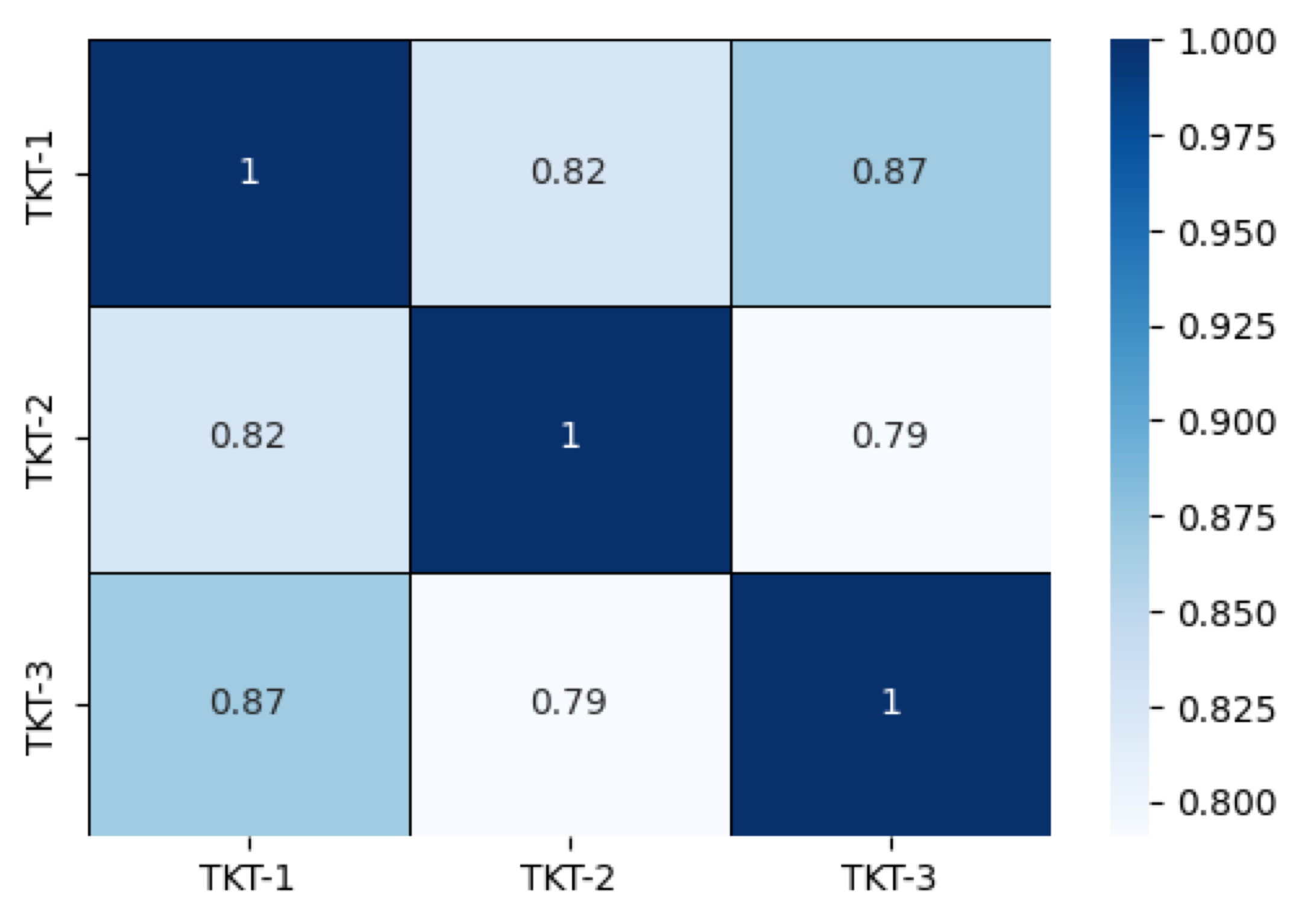
TKT-1: I have a problem with the product.
TKT-2: I would like to report an issue with the app. TKT-3: I have a problem with the people.
Why did we need a Vector Database and not a Vector Library?
Vector libraries can be used to build a highly performant prototype vector search system. FAISS an efficient similarity search & dense vector clustering library from Meta can handle vector collections of any size, even those that cannot be fully loaded into memory. Annoy from Spotify is another efficient approximate nearest neighbor search library that supports the use of static files as indexes allowing indexes to be shared across processes.
These libraries have limited functionality and are optimal to handle smaller datasets.
As dataset sizes increase and more tenants are onboarded, scaling becomes a challenge. Moreover, they don’t allow any modifications to their index data and cannot be queried during data import.
By contrast, vector databases are a more suitable solution for unstructured data storage and retrieval. They are highly scalable and can store and query millions or even billions of vectors while providing real-time responses simultaneously. We can think of the Vector Search libraries as one of the components of the vector database. The vector database offers a higher level abstraction to manage indexes, multi-tenancy and object changes. This was necessary for our system since we have multiple customers on our platform who need to keep their data isolated and searchable.
What data did we encode?
The object (ticket in our use case) contains many fields including title description and various other fields like the product or feature association and state of the ticket. It is necessary to decide on what data is most relevant to identify similarity. For the ticket similarity feature, we started with just the title and later expanded to include some of the other fields like the feature association and description to improve the search performance. We had to experiment with the fields in the object to hone in on the set that provided optimal results.
Why did we decide to build our own database?
Our platform is multi-tenant and we needed our vector database to have the capability to support tenant data isolation as well as provide fast search response times for every tenant. Another catch is that we support freemium users who may not all be active. Even with paid customers, we would only want to charge the customer for their usage. We also needed the database to handle indexes of all sizes and scale to millions of tenants.
We did not find any vector database that fit all our needs, so we decided to build our own!