

The rapid pace of innovation in AI is exciting. This paper does a great job of exploring and quantifying the rate of innovation of AI. I love how the below graph makes this point by using the number of AI/ML research publications on archive as a proxy.
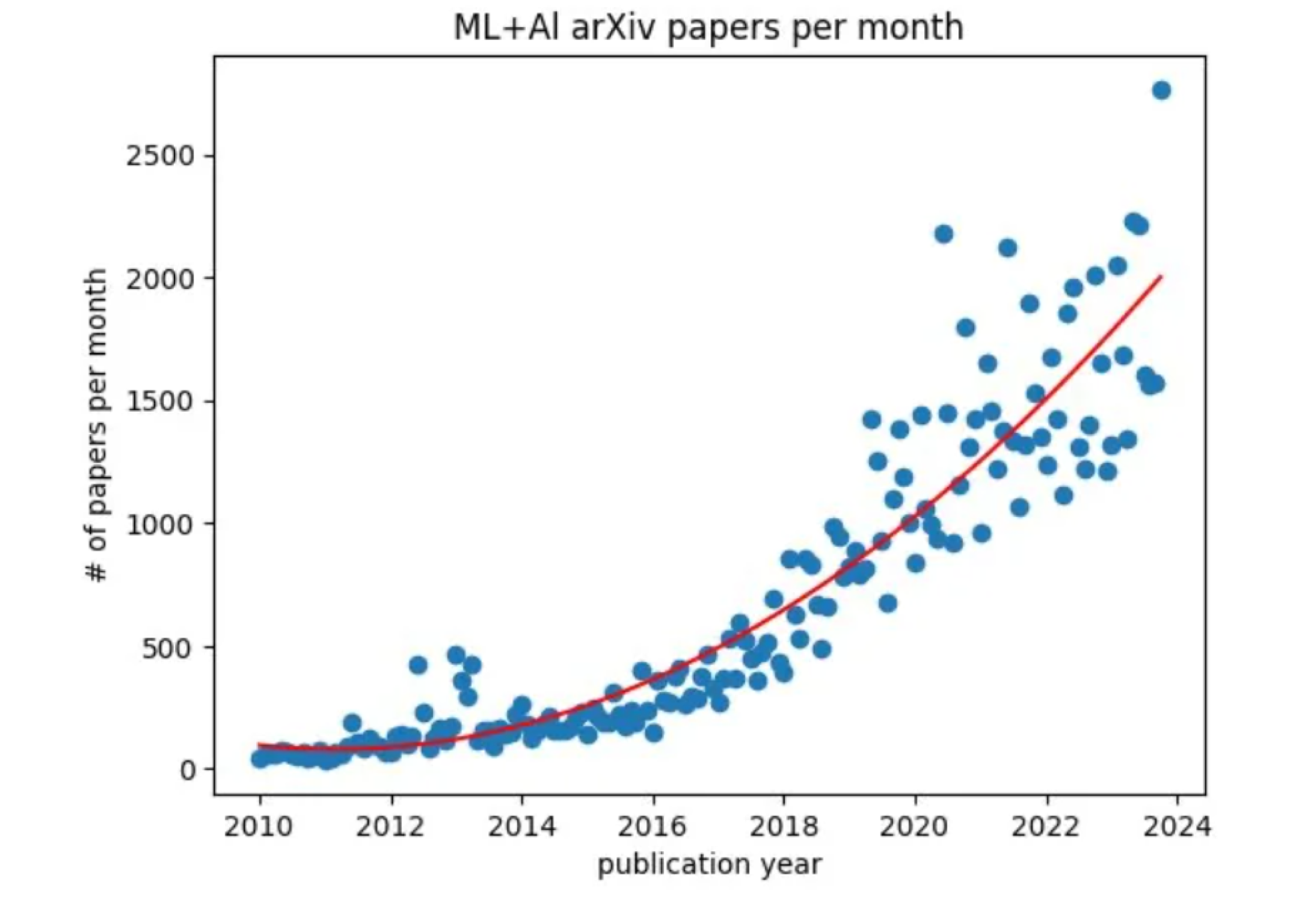
This rate of innovation does, however, pose challenges for system builders and AI application developers. The traditional approach of evaluating a set of solutions for a few months and picking the most efficient one to solve a use case will not work anymore. The ability to integrate and try different possibilities has become imperative. It has also become increasingly evident that one size doesn’t fit all for AI use cases. As the need for configurability increases in AI applications, so does the need for interface-first thinking. Good application interfaces have to be built for AI products in order to make them useful, scalable, and accurate.
The LLM agent paradigm has gained a great deal of traction and leverages tools along with the power of large language models to form intelligent digital assistants capable of performing complex tasks with natural language inputs. The tools can be used to perform deterministic tasks like database operations, making server requests, fetching data from several sources, and posting messages.
APIs (application programming interfaces) are the building blocks to developing as well as leveraging products. They provide the necessary hooks for the agent to leverage the applications and for building valuable extensions to the product.
Great APIs are necessary for building great agents and digital assistants. API design is a delicate balance between providing great usability and optimizing for system performance. I’d like to share how we designed the DevRev APIs and the tough decisions we made along the way.
To expose or not to expose: That is the question!
You can build a ton of features internally and then decide which ones you would like to expose via APIs for developers to consume or you could decide that every feature must automatically be made available via APIs. We chose the latter. This did mean more effort to design features in a modular way and avoid client specific hacks which would have shortened time to release. But it also means that we don’t spin in circles when we want to expose a feature via APIs. We also do not have to build a separate pipeline to build and support external customers vs our internal UI. All the blocks that make up DevRev Build, Support, and platform can be consumed via our APIs. This helps us address usability as well as performance concerns since we get ample feedback from our first customer, the DevRev UI. We do believe in drinking our own champagne first!
This approach helps us expose a powerful platform for developers as well as LLM Agents to leverage and build on.
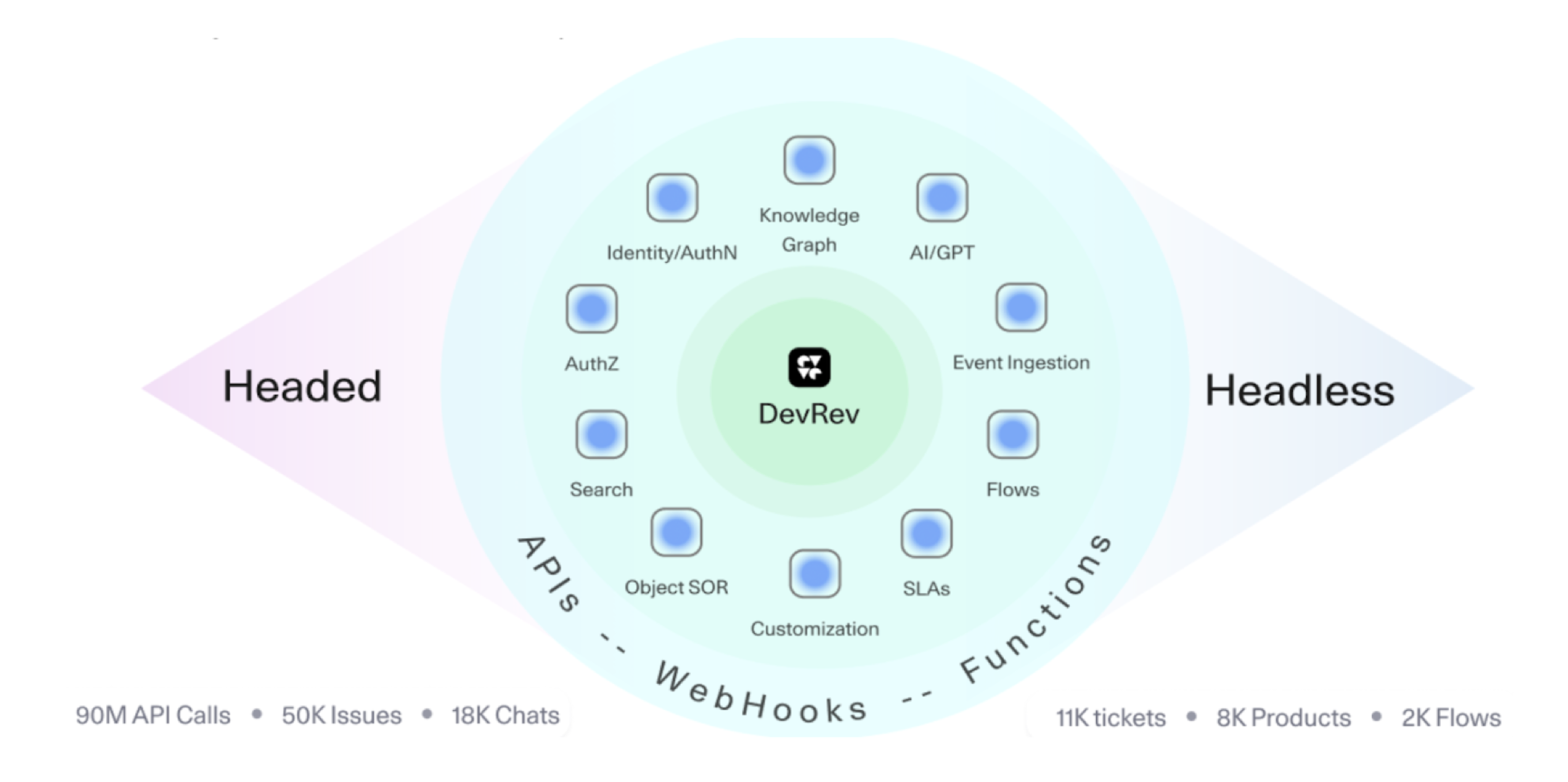
Prefer generic over specifics
As a LEGO enthusiast, I built the 10,001 piece Eiffel tower set and was blown away by how most of the LEGO pieces were reused and repurposed from earlier sets. Here is an article that talks about it. I think this echoes the merits of our decision around building generic APIs.

There are endless debates about choosing the perfect granularity for APIs. A generic API shares structure across many types or use cases, while a specific API is defined per use case. I will use an example in the context of DevRev APIs.
Ticket, issue, task, and opportunity are all types of work.
A generic API has one endpoint with multiple types.

More-specific APIs would have an endpoint for each type.

The idea behind a generic structure is to build the base object in such a way that it can be reused for multiple use cases. Generic APIs make it simpler to provide uniformity in the format, and it is easier for the user of the APIs to reason about the structure. As a developer, you rarely want to limit yourself to one particular API or use case. At the same time, it’s important to consider how much overlap the endpoints have before grouping use cases under one endpoint.
In the example above, if I looked at the DevRev /works endpoint, I would naturally become curious about opportunity, task, and ticket even if I started with the intention of using issues. Knowing about the other objects will shape how I decide to leverage or extend the DevRev platform. Of course one size does not fit all, and there is often a need to just use a specific API to accomplish a task and move on. We think this is best solved via SDKs which can provide wrappers to filter out fields and preset some defaults based on a use case. It can also be tailored to provide more abstraction and support.
From a system architecture point of view, generic APIs allow for reuse of common structures and components across many types. Since this decreases the number of individual components to be maintained, the testing, security, and maintenance efforts are more focused and robust.
Adhering to a standard specification
Any API requires a detailed description of the fields before a developer can use it. It is also only useful if it is accurate and updated in tandem with the code. We chose to adhere to the OpenAPI 3.0 Specification for DevRev APIs. This approach gives us some advantages. It helps us represent our API definitions in compliance with the industry norms and standards, and it allows the users of our APIs to use a tool of their choice to interpret, test, and generate SDKs from our published specifications.
While we do publish API documentation and our own SDK, we recognize the value of providing our customers with the freedom of choice.
We have built a generator which can interpret our protobuf definitions and generate an OpenAPI 3.1 compliant specification. The generator is executed every time there is a code change, ensuring that documentation is not an afterthought and always up to date.
Rate limiting
Protecting API endpoints from being misused and overwhelming the services serving the APIs is critical. It is important to choose rate limits that are reasonable and make them configurable to support the needs of different types of customers. We have designed the system to make it easy to modify rate limits per customer based on feedback.
System performance
Latency, throughput, scalability, and error rate are the typical measures of API performance. In order to improve these metrics, we use the following:
-
Content delivery network
Our CDN serves static content and also pre-processes requests to optimize for network latency. A layer of authorization and error checking is handled in the CDN. Moving as much intelligence as we can to the edge has been our strategy.
-
Caching
We have built an optimal in-memory caching system for low-latency retrieval.
-
Optimize network calls
The API response returns summary objects to save the client from making multiple API calls to fetch content.
-
Horizontal scaling
Kubernetes handles load by scaling the number of instances of a service. This is completely automated with no manual intervention.
-
Compression and serialization
API responses are compressed to reduce the amount of data transmitted over the network.
Using protobuf for serialization internally is faster and produces smaller payloads compared to JSON.
-
Monitoring and alerting
Every service is monitored for throughput, latency, and errors. We have an alerting system in place to inform the owners who promptly fix issues.
Security
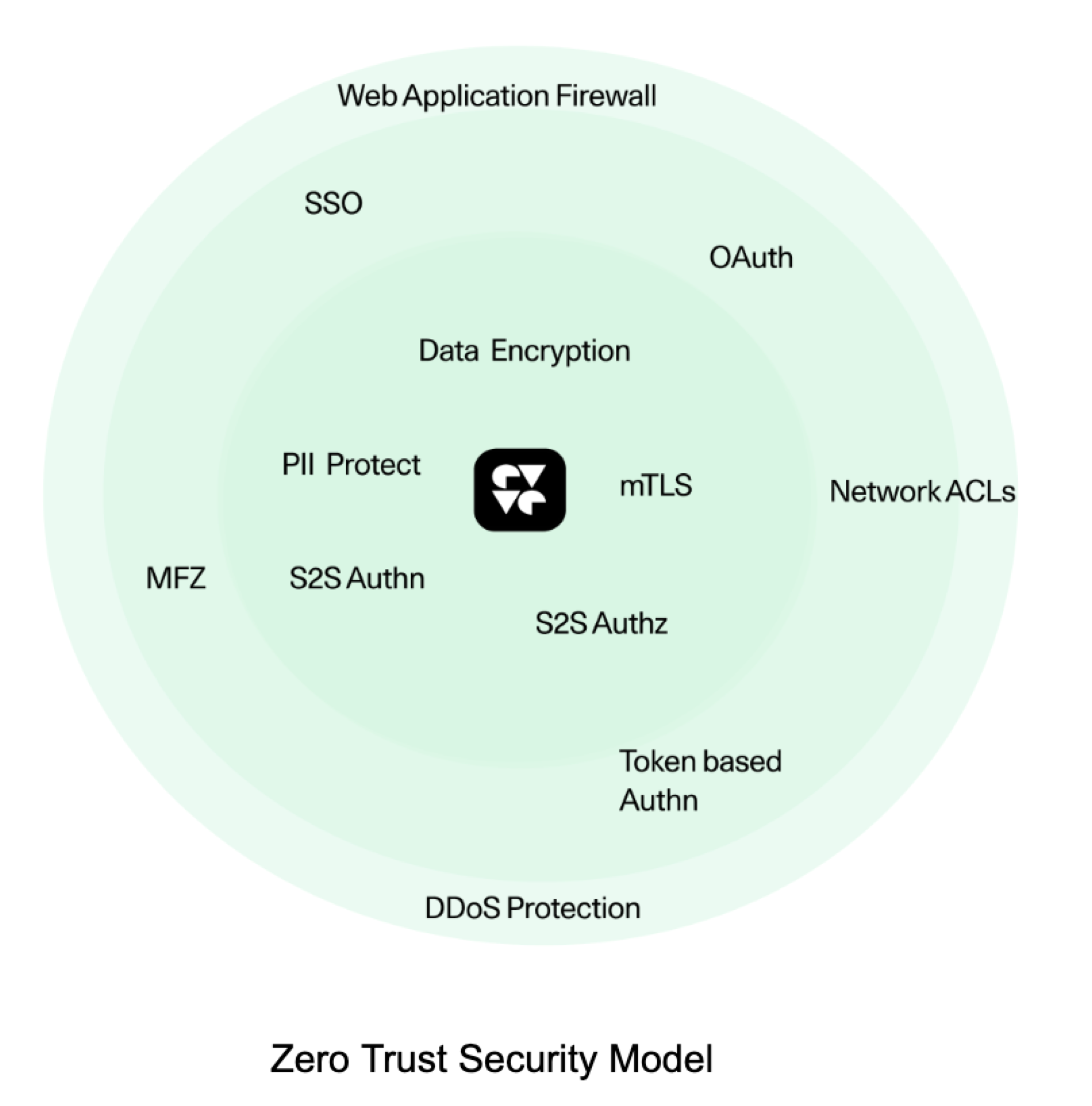
We made a choice to adopt a zero-trust security model and have built security at every layer of our platform.
We believe security is a fundamental component of API design. To automate security and enforcement, we invested in code vulnerability analysis, Terraform-based security policy management, and service-to-service mutual TLS using the service mesh.
You can see the DevRev APIs on our developer documentation site.